

AnaCredit Praxis: Herausforderung Datenqualität: Methoden, Metriken, Überprüfungen

mayato
Wie lässt sich Datenqualität bewerten? Welche Metriken und Verfahren liefern welche Ergebnisse? Der vorliegende Beitrag beschreibt die Grundlagen der Datenqualitäts-Analyse und visualisiert beispielhafte Auswertungen – zu AnaCredit. Martin Macko, Senior Consultant bei mayato, erklärt die Grundlagen im Detail.
von Martin Macko, Senior Consultant bei mayato
Der EZB-Rat beschloss am 18. Mai 2016 die Verordnung zur Implementierung eines granularen statistischen Kreditmeldewesens “ECB Regulation on the collection of granular credit and credit risk data – AnaCredit”, die zum 31. 12. 2017 in Kraft tritt. Mit dieser Verordnung werden Kreditinstitute verpflichtet, Kreditdaten und Kreditrisikodaten feingranular zu melden. Eine Ausweitung auf den gesamten Finanzsektor ist in einer späteren Ausbaustufe nach weiteren Kosten-Nutzen-Analysen möglich. Für die Kreditinstitute bedeuten AnaCredit sowie andere Initiativen wie BCBS 239 eine signifikante Investition. Sämtliche Daten müssen auf ihre Qualität geprüft sowie bestehende Datenlösungen und das Datenmanagement an die geforderten Standards angepasst werden, um die Mindestanforderungen an die Übermittlung, Exaktheit und Einhaltung von Konzepten und Korrekturen zu erfüllen.Positiv betrachtet bietet diese Pflicht aber auch die Chance, zukünftig effizienter und agiler zu agieren. Voraussetzung dafür ist die strukturierte Analyse der bisherigen Datenqualität. Basierend darauf lassen sich im nächsten Schritt entsprechende Maßnahmen ergreifen, um die Datenqualität insgesamt zu erhöhen und die zugrundeliegenden Prozesse zu optimieren.
Messung der Datenqualität für Anacredit – die Methoden
Die Datenqualität lässt sich mit unterschiedlichen Methoden bestimmen. Entscheidend ist, sich vorher darüber klar zu werden, welche dieser Methoden angewendet werden soll und diese dann kontinuierlich beizubehalten, um vergleichbare Ergebnisse zu erhalten.
Jaro-Distanz
Ähnlichkeit zwischen den Strings wird mit einer Nummer zwischen 0 bis 1 (genaue Übereinstimmung bis keine Übereinstimmung) dargestellt. Jaro-Distanz wird definiert als:
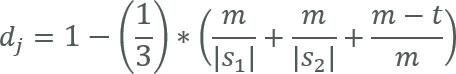
m – die Anzahl der passenden Zeichen
t – die Hälfte der Anzahl der Transpositionen
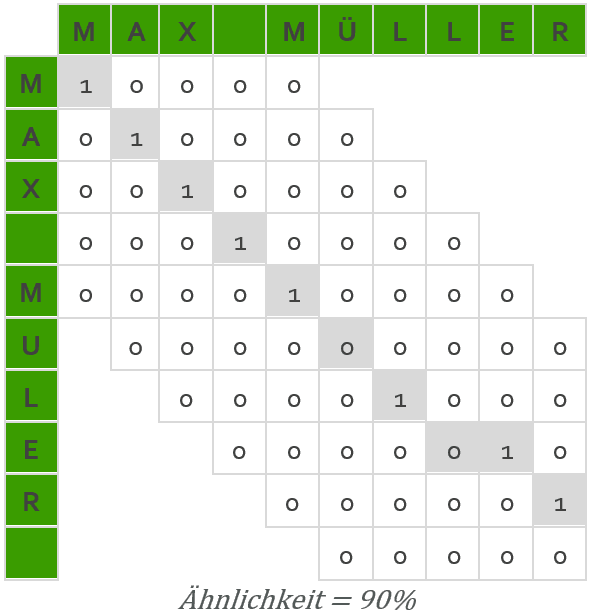
Am Beispiel von MAX MÜLLER und MAX MULER
Levenshtein-Distanz
Wird auf Basis von Anzahl der Löschungen, Einfügungen und Ersetzungen, die notwendig sind, um b ins a umzuwandeln, berechnet.

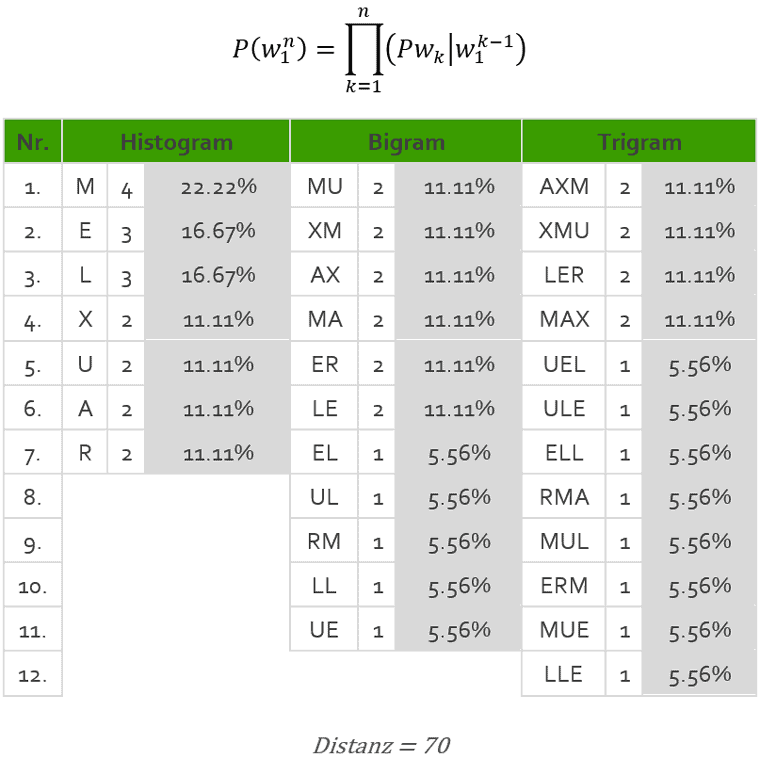
N-grams Ist eine Sequenz von unmittelbar aufeinander folgenden Lauten, Silben, Buchstaben oder Wörtern innerhalb des Strings der Länge n ohne Berücksichtigung herkömmlicher Segmentierungsgrenzen. Die N-grams lassen sich mittels eines Textfensters erstellen, die über die jeweilige Zeichensequenz geführt werden Es wird als eine Summe absoluter Differenzen zwischen N-Gramm Vektoren der Vektoren kalkuliert.
Schwellenwerte für Übereinstimmung
Je nachdem, um welche Information es sich handelt, wirken sich Datenfehler unterschiedlich aus. Um die Geschäftsauswirkungen widerzuspiegeln, lassen sich unterschiedliche Schwellenwerte festlegen. Der einfachste Ansatz ist, eine einzige Schwelle zu haben. Wenn die Konformitätsrate die Schwelle überschreitet, liegt die Qualität der Daten innerhalb akzeptabler Grenzen. Wenn die Konformitätsrate unter dem Schwellenwert liegt, ist die Qualität der Daten nicht akzeptabel. Ein umfassenderer Ansatz bietet drei Bereiche, die auf zwei Schwellen basieren: “akzeptabel”, wenn die Konformitätsrate eine hohe Schwelle erfüllt oder überschreitet, “fragwürdig, aber nutzbar”, wenn die Konformitätsrate zwischen den hohen und niedrigen Schwellen liegt und “unbrauchbar”, wenn die Konformitätsrate unter die untere Schwelle fällt.
Messung der Datenqualität – Metriken
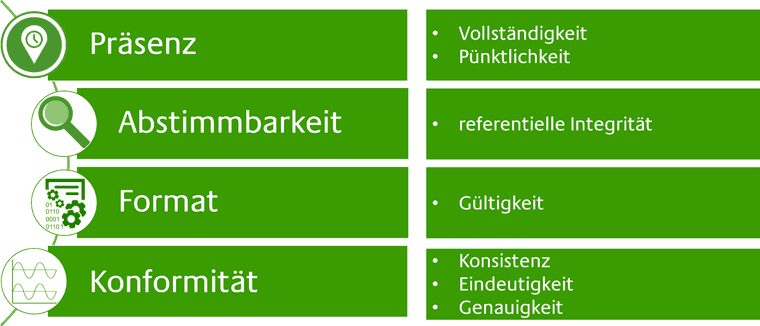
Nachdem die Methode der Messung festgelegt wurde, gilt es nun die Metriken zu definieren, auf deren Basis die Datenqualität beschrieben und bewertet wird. Sie ermöglichen schlussendlich die Analyse der Ursachen bei mangelhafter Datenqualität und die Beurteilung der DQ-Maßnahmen unter Kosten-Nutzen-Gesichtspunkten. Einen Standard, welche Metriken anzuwenden sind, existiert nicht. Hier wird eine Auswahl, basierend auf Erfahrungswerten, aufgezeigt.
Vollständigkeit
Eine Erwartung der Vollständigkeit zeigt an, dass bestimmten Attributen Werte in einem Datensatz zugewiesen werden sollen.
Beispiel: Retailkunden sind verpflichtet, die Ausweisnummer bei der Eröffnung eines Kontos auszufüllen. Die Datenanalyse wurde auf dem Datenelement „Client ID Number“ in der Tabelle Clients mit subset von Retail Clients durchgeführt. Die Analyse ergab, dass 975 Kunden von den analysierten 1’000 eine Ausweisnummer haben. Daher wurde 975/1000 = 97,5% Vollständigkeit für dieses Datenelement in der Kundentabelle erreicht.
Rechtzeitigkeit
Rechtzeitigkeit bezieht sich auf den Zeitpunkt oder Zeitraum, wann die Informationen verfügbar sein sollten. Werden die Daten zu früh oder zu spät angeliefert, sind die wertlos. Rechtzeitigkeit kann gemessen werden als die Zeit zwischen erwarteter und tatsächlicher Verfügbarkeit.
Beispiel: Daten zur Preisgestaltung der Produktinvestitionen werden oft von Drittanbietern zur Verfügung gestellt. Da der Erfolg des Unternehmens von der Zugänglichkeit abhängt, werden die Zeiten für die Preisdatenanlieferung in SLAs angegeben.
 Martin Macko begleitet als Senior Consultant der mayato AT schwerpunktmäßig Projekte in den Bereichen Data Quality Management sowie Business und Financial Analysis. Sein Master Diplom legte er in Wirtschaftswissenschaften und Management ab. Er verfügt u.a. über das SCRUM Master, IPMA, COBIT 5 und International Credit Management Zertifikate.
Martin Macko begleitet als Senior Consultant der mayato AT schwerpunktmäßig Projekte in den Bereichen Data Quality Management sowie Business und Financial Analysis. Sein Master Diplom legte er in Wirtschaftswissenschaften und Management ab. Er verfügt u.a. über das SCRUM Master, IPMA, COBIT 5 und International Credit Management Zertifikate.Referentielle Integrität
die Eigenschaft, dass zu jedem Fremdschlüssel ein Primärschlüssel in der referenzierten Relation existiert und dass die im Schema spezifizierte Multiplizität der Beziehung (1:0..1, 1:1, 1:1..*, 1:* in Unified Modeling Language) eingehalten wird.
Beispiel: Aufdeckung von Fremdschlüsseln in einer Kindrelation, zu denen kein Primärschlüssel in der Elternrelation existiert; Aufdeckung von Primärschlüsseln in einer Elternrelation, zu denen kein Fremdschlüssel in einer der Kindrelationen existiert (kein Datenqualitätsmangel, falls 1:0..1- oder 1:*-Beziehung).
Gültigkeit
Diese Dimension bezieht sich darauf, ob Instanzen von Daten entweder gespeichert, ausgetauscht oder in einem Format dargestellt werden, das mit der Domäne von Werten übereinstimmt, sowie in Übereinstimmung mit anderen ähnlichen Attributwerten. Jede Spalte hat zahlreiche Metadatenattribute, die ihr zugeordnet sind: Datentyp, Präzision, Formatmuster, Verwendung einer vordefinierten Aufzählung von Werten, Domänenbereichen, zugrundeliegenden Speicherformaten usw.
Beispiel: Der Identifikator besteht aus 2 Anfangsbuchstaben des Vornamens 2 Anfangszeichen des Nachnamens, gefolgt von 4 Ziffern der Personenabteilung (z. B. MaMü1424)
Konsistenz
In ihrer grundlegendsten Form bezieht sich Konsistenz auf Datenwerte in einem Datensatz, der mit Werten in einem anderen Datensatz übereinstimmt. Eine strikte Definition der Konsistenz legt fest, dass zwei Datenwerte, die aus separaten Datensätzen gezogen werden, nicht miteinander in Konflikt stehen dürfen, obwohl Konsistenz nicht zwangsläufig Korrektheit bedeutet. Weitere formale Konsistenzbeschränkungen können als ein Satz von Regeln eingekapselt werden, die Konsistenzbeziehungen zwischen Werten von Attributen entweder über einen Datensatz oder eine Nachricht, oder über alle Werte eines einzelnen Attributs spezifizieren. Übereinstimmung mit Genauigkeit oder Richtigkeit darf nicht mit Konsistenz verwechselt werden.
Konsistenz kann in verschiedenen Kontexten definiert werden:
1. Zwischen einem Satz von Attributwerten und einem anderen Attribut, das innerhalb des gleichen Datensatzes gesetzt ist (Aufzeichnungsniveaukonsistenz)
2. Zwischen einem Satz von Attributwerten und einem anderen Attribut, das in verschiedenen Datensätzen gesetzt ist (Cross-Record-Konsistenz)
3. Zwischen einem Satz von Attributwerten und demselben Attribut, das innerhalb des gleichen Datensatzes zu verschiedenen Zeitpunkten gesetzt ist (zeitliche Konsistenz)
4. Die Konsistenz kann auch den Begriff der “Angemessenheit” berücksichtigen, in dem ein gewisses Maß an Akzeptanz den Werten eines Satzes von Attributen auferlegt wird.
Beispiel: Eröffnungsdatum des Kundenkontos liegt nach dem Datum der Kontoschließung (zeitliche Konsistenz)
Eindeutigkeit
Eindeutigkeit bezieht sich auf Anforderungen, die im Unternehmen modellierte Einheiten erfasst und in den jeweiligen Anwendungsarchitekturen eindeutig dargestellt werden. Die Einhaltung der Eindeutigkeit der Entitäten innerhalb eines Datensatzes impliziert, dass keine Entität mehr als einmal innerhalb des Datensatzes existiert und dass es einen Schlüssel gibt, der verwendet werden kann, um auf jede Entität (und nur diese bestimmte Entität) innerhalb des Datensatzes eindeutig zuzugreifen. Beispielsweise muss in einer Master-Produkttabelle jedes Produkt einmal erscheinen und ihm eine eindeutige Kennung zugewiesen werden, die es über die Client-Anwendungen repräsentiert.
Beispiel: Eine Filiale hat 300 aktuelle Kunden und 700 ehemalige Kunden (d. H. 1.000 insgesamt) aber das Data Warehouse zeigt 1.050 verschiedene Kundenakten. Dies könnte Max Müller und Max Mueller als separate Aufzeichnungen enthalten, obwohl es nur einen Kunden namens Max Müller in der Filiale gibt.
Dies zeigt eine Eindeutigkeit von 1.000/1.050 x 100 = 95,23%
Genauigkeit
Die Datengenauigkeit bezieht sich auf den Grad, mit dem Daten korrekt die Objekte darstellen, die sie modellieren sollen. In vielen Fällen wird die Genauigkeit gemessen, wie die Werte mit einer identifizierten Quelle korrekter Informationen (wie Referenzdaten) übereinstimmen. Es gibt verschiedene Quellen von korrekter Information: eine Datensatzliste, eine ähnliche Korrektur von Datenwerten aus einer anderen Tabelle, dynamisch berechnete Werte oder vielleicht das Ergebnis eines manuellen Prozesses.
Beispiel: Registrierungsadresse des Unternehmens muss vollständig (ohne Abkürzungen ausgefüllt werden).
z.B.: “Flughafen” nur als “Flugh.” oder “Martin Luther King Boulevard” als “MLK Blvd” abgekürzt.
Arten von Prüfungen
Nachdem nun festgelegt wurde, nach welchen Methoden die Datenqualität insgesamt bewertet und welche Metriken als Basis gewählt werden soll, bieten sich unterschiedliche Möglichkeiten, um die Daten im Rahmen eines DWH-Internes Kontrollsystems zu prüfen. Diese werden im Folgenden beschrieben, wobei sich die Darstellung auf Bestandsprüfungen beschränkt, die “offline” nach der Fortschreibung der Daten erfolgt.
Verlaufsprüfungen: Erkennen von “Sprüngen”, Verlaufsreporting
Diese Prüfungen bieten die Möglichkeit, Verläufe zu beobachten und sprunghafte Veränderungen zu erkennen. Die Ergebnisse müssen unter Beachtung fachlicher Gründe immer interpretiert werden. Das heißt, gab es fachlich begründete Ereignisse, die eine Veränderung des Verlaufes ausgelöst haben, bedeutet das keinen Fehler. Sprünge werden im Fehlerfall meist durch fehlerhafte (also unvollständige oder doppelte) Verarbeitung innerhalb des DWH ausgelöst. Für die Analyse und das Erkennen von solchen Fehlerfällen sollten primär Vergleichsprüfungen verwendet werden, da sich diese besser auf Prüfstrecken eingrenzen lassen und kaum fachlich interpretiert werden müssen. Verlaufsprüfungen können jedoch auf Datamarts bzw. im BL angewendet, ein zusammenfassendes Qualitätsreporting bieten.
Vergleichsprüfungen: Vollständigkeit in der Verarbeitung (inkl. Inaktivierung)
Diese Prüfungen zeigen Unterschiede zwischen zwei Tabellen und können dadurch die korrekte Verarbeitung zwischen ihnen prüfen. Dabei sind grundsätzlich drei Ergebnisse zu erwarten. Die Anzahl/ das Volumen weicht von einer Tabelle zur anderen nach oben (“zu viel”) oder nach unten (“zu wenig”) ab oder unterscheidet sich nicht. Dabei ist jedoch zu beachten, dass die Prüfungen schlüsselbasiert umzusetzen sind. Das bedeutet, dass nicht nur die aggregierten Ergebnisse miteinander verglichen werden dürfen, sondern jeder Schlüssel eines geprüften Objektes (z.B. rsVertrag) verknüpft werden muss.
Inhaltsfehlerprüfungen: Plausibilität, fachliche Korrektheit
Diese Prüfungen resultieren oft aus bekannten Inhaltsfehlern, die in der Regel auch bereits aus dem Quellsystem übernommen wurden. Bei der Konzeption werden zumeist Wenn-Dann-Regelwerke verwendet (“Wenn Produktschlüssel 123, dann muss Zahlweise gleich ’12’ sein”) oder nur einzelne Felder geprüft (“Betrag darf nicht <blank> sein”). Es ist hierbei unvermeidlich, Teile von Logiken des DWH im IKS “nachzubauen”. Die Auswahl der so verwendeten Prüfungen ist daher auf die kritischen Aspekte zu begrenzen, um den Wartungsaufwand bei Änderungen der Logik im DWH möglichst gering zu halten. Bei diesen Prüfungen sind auch “Warnungen” in Form von Prüflisten möglich (siehe Schwere). Aufgrund des hohen manuellen Analyseaufwandes, der zur Identifikation tatsächlicher Fehler notwendig ist, sollten diese weitgehend vermieden werden.
Data Quality Indicator – Lifecycle Process
Um die Datenqualität als festen Bestandteil zu integrieren, sollte ein fester Prozess mit entsprechenden Verantwortlichen definiert und implementiert werden. Wie dieser aussehen kann, zeigt dieses Schaubild:
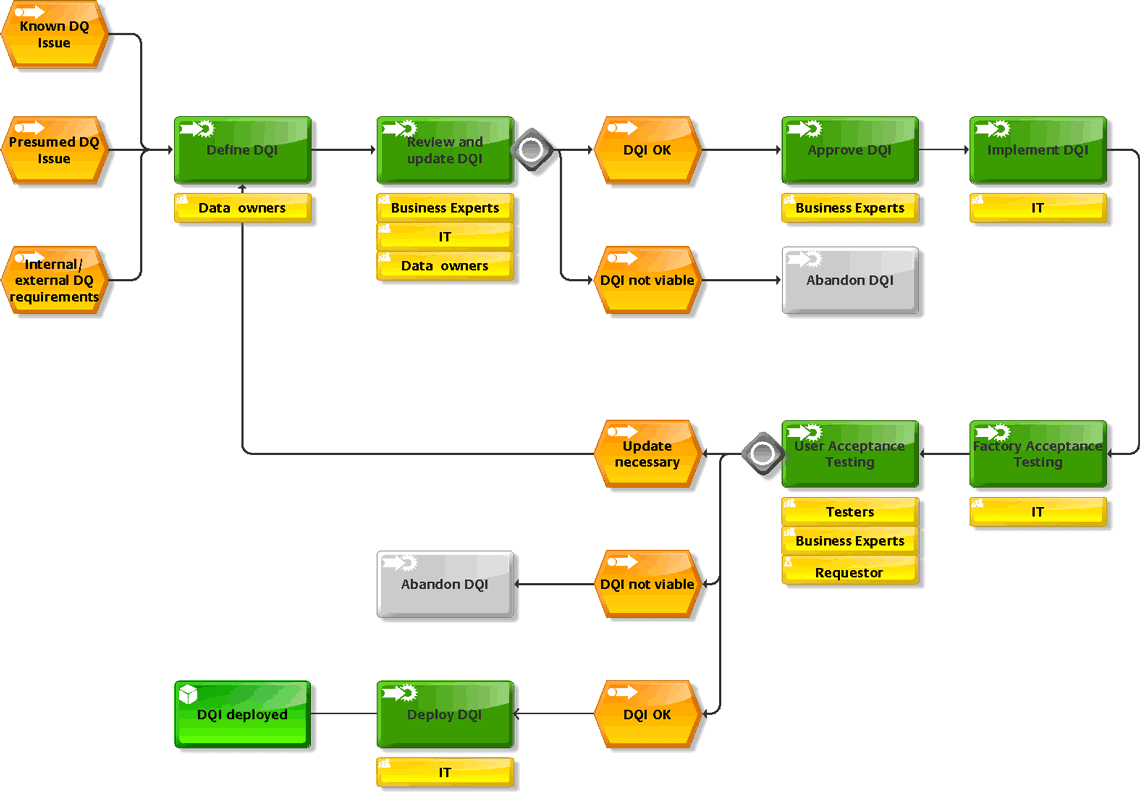
KPIs Reporting – Dashboard
Am Ende des gesamten Prozesses steht dann die tatsächliche Bewertung der Datenqualität in den einzelnen Bereichen. Hier bieten Dashboards eine rasche visuelle Übersicht des aktuellen Datenqualitätsdurchschnitts als auch der Entwicklung des DQ in den letzten Monaten auf Länderebene.
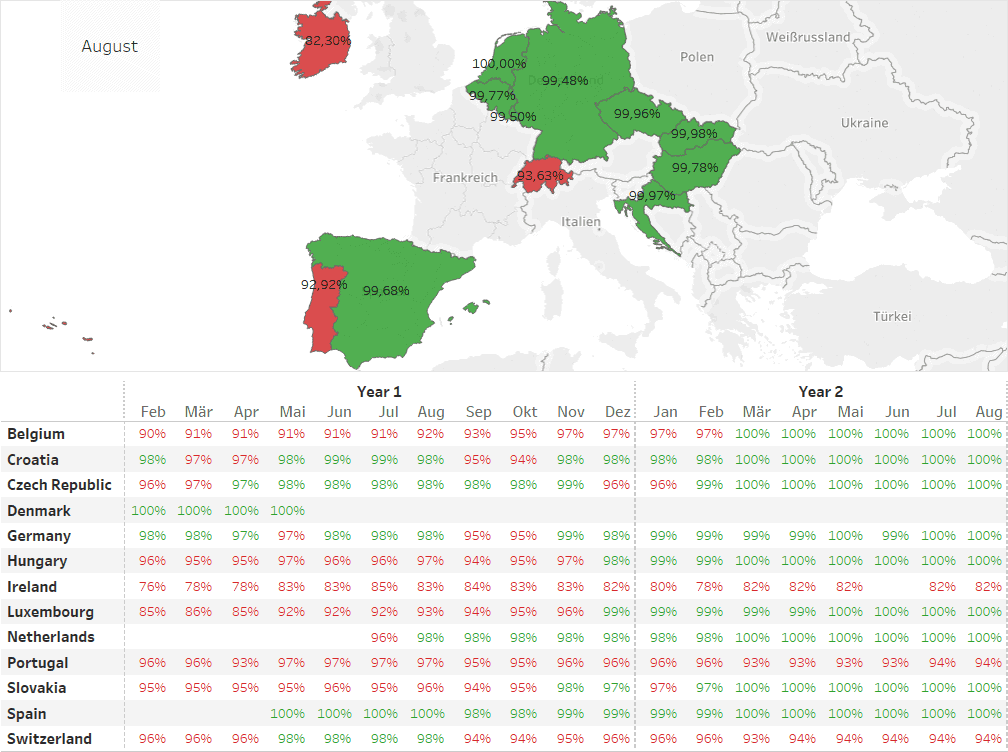
KPIs Reporting – Dashboard – Länderauswahl
Sobald man ein Land auswählt, zeigt sich eine Übersicht der Datenqualität auf Indikatorebene.
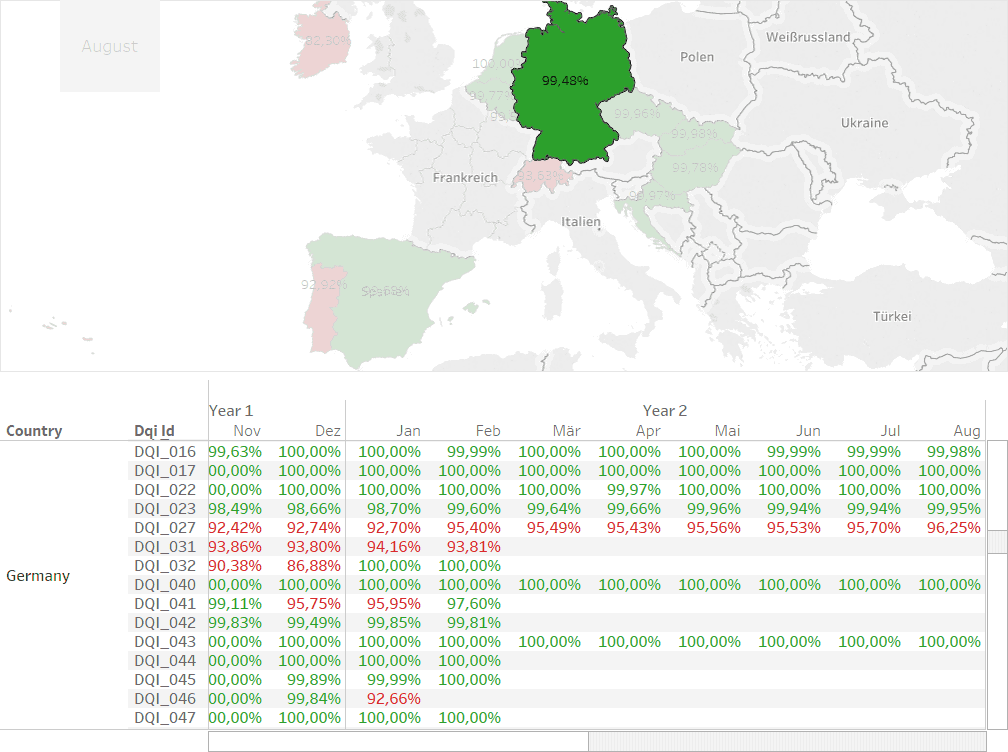
Fazit
In vielen Datenbanken liegen die feingranularen Werte, wie sie AnaCredit fordert, noch nicht vor bzw. deren Qualität ist nicht gewährleistet. Die EZB verfügt aber durchaus über Möglichkeiten, die Korrektheit der gelieferten Daten zu prüfen. Im Zuge der Verfeinerung ihrer Daten, sollten die Banken jetzt die Chance nutzen, ihre Datenqualität zu prüfen und zu verbessern.
Die Erfahrung zeigt, dass damit langfristig nicht nur die Risiken minimiert, sondern auch die Kosten deutlich gesenkt werden.aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/61834


Schreiben Sie einen Kommentar