

Informationen intelligent extrahieren: vom Dokumentenchaos zur strukturierten Datenanalyse

Actineo
In der Versicherungsbranche werden ausscheidende Mitarbeitende mit Jahrzehnte langer Erfahrung in der Schadensregulierung bald eine klaffende Lücke hinterlassen. Ihr Wissen ist zwar implizit in den hauseigenen Systemen gesichert, geht aber trotzdem verloren, weil Mentoren für jüngere Kollegen fehlen. Die gute Nachricht: In den IT-Systemen der Versicherer schlummern enorme Wissensschätze in Form von Daten. Sie müssen nur geborgen werden, um Schäden weiterhin mit generationsübergreifendem Know-how regulieren zu können.
von Marco Meisen, Geschäftsführer & CTO, und Sebastian Steinfort, Head of Data & Analytics, bei Actineo

Actineo
Einfach für den Menschen, eine Challenge für die Maschine
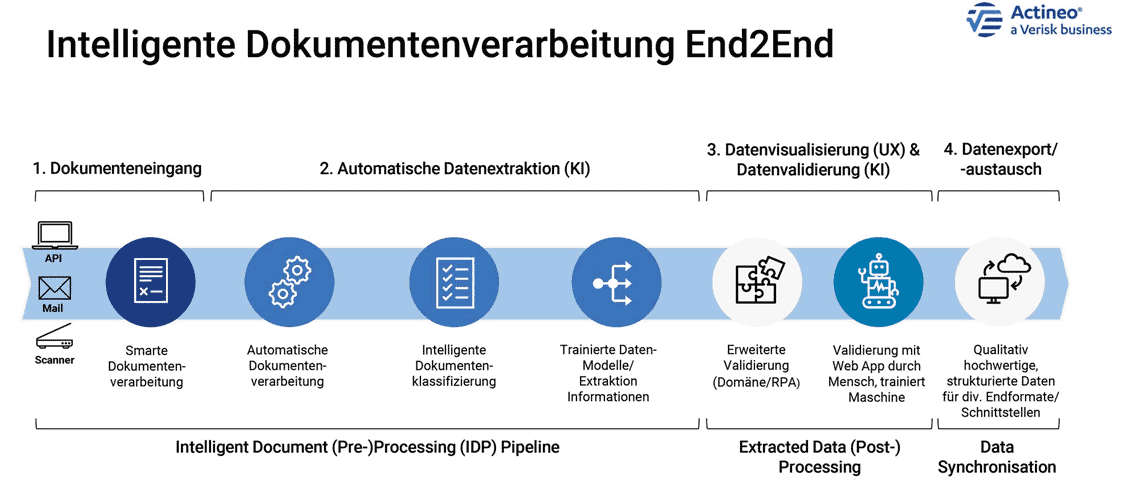
Egal ob Klinikbericht, Leistungsrechnung zu Mensch oder Tier, Anwaltsschreiben, Handwerkerrechnung oder Werkstattreport – grundsätzlich können Anwender mithilfe einer digitalen Anwendung jede Art von Dokument in unbegrenztem Umfang digitalisieren, strukturieren und handhabbar machen. Mittels Optical Character Recognition und Machine-Learning-Modellen liest ein solches Tool komplexe (medizinische) Akten, zerlegt diese in die einzelnen Komponenten, strukturiert Dokumente, klassifiziert diese und eliminiert Dubletten. In einem Folgeschritt werden relevante Daten wie Stammdaten, Diagnosen, Behandlungsempfehlungen oder Dauerschadeneinschätzungen aus den Dokumenten ausgelesen.
Was für einen Menschen einfach erscheint – vergisst man bei der Betrachtung die jahrelange Schul-, Aus- und Weiterbildung –, ist für eine Maschine immer noch eine schwierige Aufgabe. Um strukturiert die richtigen Informationen aus einem Dokument zu extrahieren, bedarf es mehrerer Schritte. Ein Modell muss in der Lage sein, das Layout des Dokuments zu erkennen und daraus Beziehungen zwischen Informationen abzuleiten, um wichtige Passagen oder relevante Stichworte extrahieren zu können. Ein solches Modell kann nur bis zu einem gewissen Grad generalistisch trainiert werden, da sich Strukturen von Dokumenten länderspezifisch unterscheiden. Es ist selbst für eine fachlich erfahrene Person schwierig, Dokumente aus einem anderen Kulturkreis zu verstehen.

Actineo
Sebastian Steinfort ist Diplom-Informatiker und Wirtschaftspsychologe (M.Sc.). Nach seinem Informatikstudium an der Universität Dortmund arbeitete er zunächst als C# .Net-Entwickler bei verschiedenen Unternehmen. Bei der AUTOonline stieg Sebastian Steinfort vom Product Owner zum Business Development Manager mit dem Schwerpunkt Produktentwicklung aus Daten auf. Bei der Audatex AUTOonline bestimmte er – zuletzt als Produkt Manager – den Erfolg des auf integriertes Kfz-Schadenmanagement ausgerichteten Dienstleisters mit. Bevor er zu Actineo (Website) wechselte, hatte Sebastian Steinfort bei ControlExpert schließlich die Teamleitung Business Intelligence inne. Bei Actineo verantwortet er die Entwicklung von digitalen Produkten für die Personenschadensregulierung, die auf Prädikationsmodellen, Deep Learning, und Künstlicher Intelligenz beruhen.
Für die erfolgreiche Extraktion der richtigen Daten ist eine Kaskade an unterschiedlichen Modellen beteiligt. Am Anfang steht die Bestimmung, ob in der zu verarbeiteten Datei mehr als ein Dokument enthalten ist.
Durch Bestimmung der Dokumentenart werden zusammenhängende Dokumente erkannt und entsprechend unterteilt. Durch diese Unterteilung ergibt sich der Kontext der Extraktion, ohne den die gefundene Informationen ohne Wert wären, da ihr Zusammenhang im Prozess unbekannt bliebe.”
Einfache Daten, wie Namen oder Datumsangaben können mit einfacher Validierung übernommen werden. Andere Informationen müssen weiterverarbeitet werden, zum Beispiel eine Anamnese oder ein Befund aus einem Arztbrief, da die enthaltenen Diagnosen und deren medizinische Kodierung nach ICD-10 von Interesse sind.
Use Cases aus allen Bereichen des Versicherungsgeschäftes
Die Visualisierung, die automatische Validierung und der manuelle Abschluss findet nach Regelwerken statt, die gemeinsam mit dem jeweiligen Versicherungskunden konfiguriert werden. Die Anwendungsfälle müssen dabei nicht zwangsläufig aus dem Schadensbereich kommen. Es sind auch Use Cases aus allen anderen Bereichen des Versicherungsgeschäftes denkbar. Die Daten stehen anschließend visuell in den Schadensystemen des Dienstleisters oder in anderen (Web-)Applikationen zur Verfügung.
Ebenso wie die Machine-Learning-Modelle in der Lage sein müssen, in unterschiedlichen Dokumentenarten andere Stichworte und ihre Bezüge zu finden, so muss die Applikation in der Lage sein, diese entsprechend ihrem Datenformat anzuzeigen und zu validieren.
Durch die Klassifikation der Dokumente ist bekannt, welche Informationen aus dem Dokument extrahiert werden müssen, und welches Datenformat erwartet wird. Die Anwendung selbst muss dann dynamisch zum Dokumententyp die Darstellung anpassen und entsprechende Validierung der gefundenen Daten vornehmen, sodass einem Mitarbeitenden erleichtert wird, zu erkennen, an welcher Stelle Unsicherheiten bei den gefundenen Daten oder Fehler vorliegen, falls eine Validierung fehlschlägt oder mehr als ein Treffer gefunden wurde.
Kundenschnittstellen flexibel anbinden
Lange Zeit führten vor allem Limitierungen auf Kundenseite dazu, dass die einzige Repräsentation der extrahierten Schadendaten eine Zusammenfassung in Form eines PDF-Dokuments war. Die Möglichkeit, Informationen in den Bestandssystemen auch auf andere Arten zu verarbeiten, besteht erst seit Kurzem. Diese Entwicklung ist zu begrüßen, da Kunden so besser datenbasiert unterstützt und Daten ohne Doppeleingaben seitens der Versicherungssachbearbeitenden direkt in den Systemen verarbeitet werden können.
Daraus entstehen allerdings auch neue Herausforderungen. Unterschiedliche Kundenanforderungen bedeuten nicht mehr nur visuelle Änderungen in einem PDF-Dokument. Als Übertragungswege wird es ferner neben der GDV-Schnittstelle verschiedenste API-Anbindungen in die Backends der versicherungseigenen Systeme geben, um dort dieselben Informationen in einem Format und einer Struktur zu übertragen, die nach Kunde, Sparte oder sogar Abteilung unterschiedlich sein können.
Jeder Fachbereich wird seinen eigenen Schwerpunkt bei den zu extrahierenden Daten haben, um seine Arbeit effizienter zu gestalten.”

Actineo
Marco Meisen, diplomierter Kaufmann und Wirtschaftsinformatiker, ist seit Januar 2021 als Geschäftsführer (CTO) ein Teil des Managementteams bei Actineo (Website). Er hat viel Erfahrung in agilen Softwareorganisationen und blickt auf mehr als fünfzehn Jahren Führungserfahrung zurück. 2010 wurde Meisen Head of Engineering und Agile Coach bei d.velop, einem führenden Anbieter von Enterprise-Content-Management-Systemen. Von 2013 bis 2017 war er Teamleiter beim Technologieberatungsunternehmen Cassini Consulting. Zuletzt agierte Marco Meisen als Chief Technology Officer bei Chefkoch, einem Gruner+Jahr-Webportal und Europas größter Food-Plattform.
Um dieser Entwicklung zu begegnen, sollte die Plattform ein flexibles Schnittstellenmanagement in Kombination mit einer Komponente zur Datentransformation bieten. So können Kundenschnittstellen flexibel angebunden und unabhängig davon die Daten in die geforderte Form transformiert werden. Das heißt konkret, der Versicherer könnte beispielsweise die Übermittlung per GDV, API oder SFTP-Upload wünschen und die eigentlichen Daten könnten in Formaten wie JSON, XML, Excel oder CSV übermittelt werden. Dabei spielt es keine Rolle, ob die Daten binär, Base64 oder anderweitig enkodiert werden müssten. Durch diese unabhängige Kopplung wird die maximale Integration in bestehende, aber auch künftige Systeme erreicht, um bei Bedarf alle Daten im eigenen Bestandssystem weiterverarbeiten zu können.
Wissenstransfer integrieren: ein Muss
Schadensdienstleister können Versicherungen datenbasiert sowohl in der Bearbeitung von laufenden Schadensfällen als auch in der Analyse historischer Datenbestände unterstützen. Damit ist es heute schon möglich, dem Sachbearbeiter auf Basis der Falldaten automatisiert Vorschläge zu machen, wie der Schaden reguliert werden kann. Künftig sollten auch hauseigene historische Daten integriert werden, um den Wissenstransfer implizit zu integrieren und den Effekten des drohenden Mitarbeiterschwunds entgegenzuwirken.Marco Meisen und Sebastian Steinfort, Actineo
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/162246


Schreiben Sie einen Kommentar