
Machine Learning ist leichter als man denkt!

Sollers Consulting
Aufgrund vermeintlich hoher Komplexität tun sich Versicherer (und Banken) mit dem Einsatz von Machine Learning bislang schwer. Ein Praxisfall zeigt, dass mit relativ wenig Aufwand bereits sichtbare Erfolge erzielt werden können.
von Michal Trochimczuk, Managing Partner und Marcin Grabowski, Managing Consultant bei Sollers Consulting
Die Herausforderung für Finanzinstitute besteht schon lange nicht mehr darin, genügend Daten zu sammeln. Laut Tim Stack von Cisco gibt es allein 5 Trillionen (5 x 10 18 ) Bit Daten, die täglich von IoT-Geräten generiert werden (mehr dazu…).Die Herausforderung besteht darin, diese Daten nutzbar zu machen, um greifbare Erkenntnisse zu erhalten, die positive Auswirkungen auf das Geschäft haben.”

Sollers Consulting
Die Arbeit mit derartigen Datenmassen erfordert unkonventionelle Ansätze. So werden Machine Learning und Künstliche Intelligenz kontinuierlich weiterentwickelt. Die Anwendung dieser Methoden kann dazu beitragen, zahlreiche Vorteile nutzbar zu machen. Scott Seely, Principal Solutions Architect bei Microsoft, definiert acht Use Cases für die Versicherungswirtschaft:
1. Storno-Management, um den Wegfall von Bestandskunden zu begrenzen,2. Beratungs-Engines, die Bedarfslücken und Versicherungssummen für Kunden ermitteln und vorschlagen,
3. Schadenregulierungsassistenten, welche viele manuelle Prozesse automatisieren, die während der Schadenaufnahme durchgeführt werden,
4. Schadensaufnahme, insbesondere bei großen Kumulschäden,
5. Betrugserkennung, Anwendung automatisierter Mechanismen für die proaktive Prävention,
6. Personalisierte Angebote, die das Kundenerlebnis durch die Bündelung von Deckungen aus verschiedenen Geschäftsbereichen und Zusatzleistungen verbessern,
7. Prädiktive Analysen, die helfen, die Schadenshäufigkeit vorherzusagen,
8. Skaliertes Training von Modellen mit GPUs oder tausenden von CPU-Kernen (mehr dazu…).
Wie sehr jeder dieser Use Cases bereits von den Versicherern genutzt wird, variiert stark. Auf dem Markt gibt es relativ viele Unternehmen, die bereits Machine Learning zur Betrugserkennung oder Schadenregulierungstools einsetzen. Gleichzeitig gibt es bislang relativ wenige Anwendungen von Versicherungsberatungssoftware oder personalisierender Angebotssoftware.
Die Vielzahl an bestehenden Kundendaten aus den Kernsystemen bietet zahlreiche Möglichkeiten, das Versicherungsgeschäft mit wertvollen Einsichten zu unterstützen. Ausgehend von der Machine Learning-Analyse können Schlussfolgerungen beispielsweise die Effektivität von Cross-Selling-Kampagnen der Versicherer erhöhen. Dies kann durch die Beantwortung folgender Fragen erreicht werden:
Welche Kunden, die über Produkt A (z.B. Kreditkarte) verfügen, sind eher bereit, Produkt B (z.B. Reiseversicherung) zu kaufen?
Wann ist der ideale Zeitpunkt, um den Kunden ein bestimmtes Produkt anzubieten?
Wir haben uns entschieden, h2o.ai einzusetzen, da es als eine der führenden Plattformen für Machine Learning weit verbreitet ist und auf Open-Source-Basis operiert. Die technologische Umsetzung gestaltet sich relativ einfach.”
Machine Learning wird in der Versicherungsbranche trotz all seiner Vorteile viel seltener eingesetzt als es bereits möglich wäre. Die meisten Unternehmen betrachten es als eine äußerst komplexe Technologie und entscheiden sich daher tendenziell gegen alle Initiativen, die ihren Einsatz vorantreiben würden.”
Laut Uniserv wird dieses Argument von 53 Prozent der Entscheider im Banking- und Versicherungsbereich als entscheidend für den Verzicht auf Maschine Learning oder künstlicher Intelligenz genannt. Das überrascht kaum, denn eine sinnvolle Nutzung erfordert technologisches Know-how, mathematisches Fachwissen und tiefe Branchenkenntnisse. Zusammengenommen kann so der Prozess ganzheitlich zu Business-orientierten Zielen hingeführt werden.
Es ist allerdings so, dass der sinnvolle Einsatz von Machine Learning einfacher ist, als allgemein angenommen wird. Es gibt viele Data-Science-Plattformen auf dem Markt, einige von ihnen arbeiten nach dem Open-Source-Prinzip, z.B. h2o.ai .”
Natürlich ist weiterhin Branchenwissen erforderlich, um die Daten zu verstehen, die wichtigsten Datenpunkte auszuwählen und die Machine-Learning-Lösung in die richtige Richtung zu lenken, um wertvolle und umsetzbare Einblicke zu generieren. Die Erstellung geeigneter Algorithmen kann natürlich sehr komplizierte Berechnungen umfassen, aber schon relativ einfache mathematische Operationen helfen, aussagekräftige Ergebnisse zu erhalten.
Der Ansatz besteht darin, ein Versicherungskernsystem mit der h2o.ai Engine zu integrieren und die Engine mit einer Trainingsdatei mit Kundendaten zu versorgen und maschinelle Lernen auf den Datensatz anzuwenden. Natürlich muss die Datei strukturierte und relevante Informationen enthalten, einschließlich ausgewählter personenbezogener Daten, Vertragsdaten, Schadensfalldaten oder Transaktionsdaten. Das folgende Schema zeigt, welche Architektur angewendet werden kann, um h2o.ai umzusetzen.
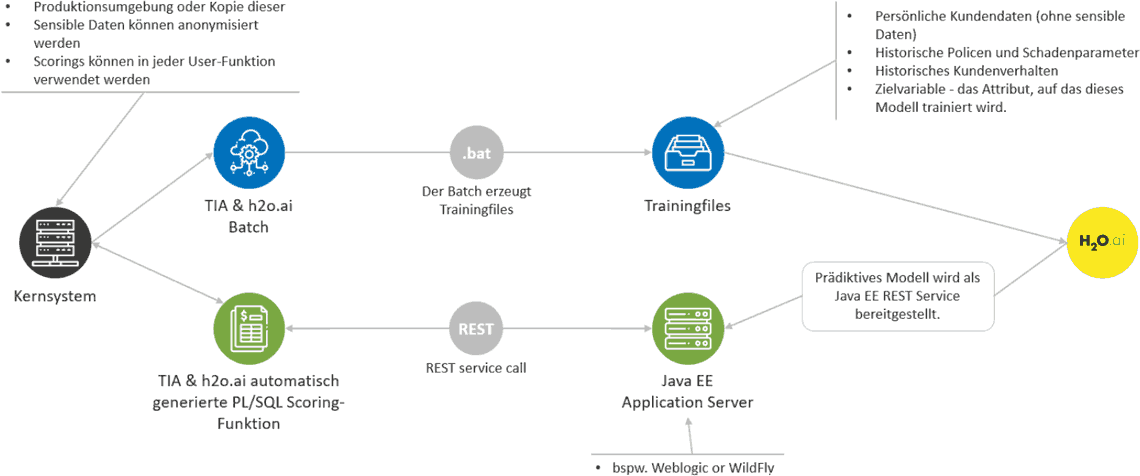
Sollers Consulting
Die Erstellung eines solchen Modells erfordert nur wenige Wochen und ein überschaubares Team. Dies zeigt, dass keine großen Investitionen und monatelangen Projekte erforderlich sind, um frühzeitig Nutzen zu ziehen und den Mehrwert von Machine Learning für das eigene Unternehmen zu bewerten.”
Die Bestätigung des Nutzens für das Geschäft ist dabei von größter Bedeutung. Wolfgang Wahlster, Gründer und langjähriger Geschäftsführer des Deutschen Forschungszentrums für Künstliche Intelligenz, merkte in einem Interview an: “Ich habe bereits drei Hype-Zyklen für KI gesehen – es ist sehr wichtig, wie ich unseren Forschern sage, nicht zu viel zu versprechen und zu wenig zu leisten” (mehr dazu…). Trotz des medialen Hypes gibt es immer noch relativ wenig verifizierte Business Cases für Machine Learning und Künstliche Intelligenz im Versicherungswesen.
Es ist leicht, sich in Trend- und Zukunftstechnologien zu engagieren und erhebliche Ressourcen für Projekte bereitzustellen. Viele dieser Initiativen mögen auf den ersten Blick interessant sein, werden aber voraussichtlich keine nennenswerten Resultate liefern, die den hohen Aufwand rechtfertigen. Wie in einer Analyse der BCG beschrieben, ist in einem schwer voraussehbaren Markt wie dem des Machine Learning und der künstlichen Intelligenz eine adaptive Strategie vonnöten (mehr dazu…). Dies bedeutet, eine Reihe kleiner, kostengünstiger Proof-of-Concepts zu entwickeln, die auf die Validierung verschiedener Business Use Cases abzielen. Diejenigen, die die vielversprechendsten Ergebnisse liefern, müssen dann skaliert werden.
Der Weg zu einem verifizierten Use Case für Machine Learning ist nicht banal, doch es gibt simple erste Schritte, die man gehen sollte.”
Es bedarf eines bewährten Partners, um diesen Weg zu gehen und Fähigkeiten bereitzustellen, die im Talentpool eines Unternehmens fehlen, insbesondere in Bezug auf die Verwaltung von Data-Science-Plattformen, die Bereitstellung von Algorithmen und die Einrichtung technischer Lösungen, die für die effiziente Anwendung von Machine Learning für ein Versicherungsunternehmen erforderlich sind.Michal Trochimczuk und Marcin Grabowski, Sollers Consulting
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/89717


Schreiben Sie einen Kommentar